Methodology
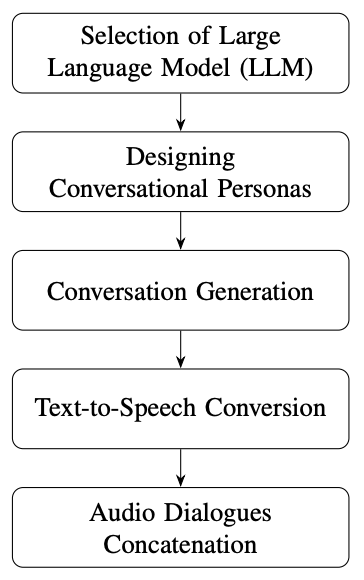
Our approach is structured around key stages, including the selection of a suitable large language model (LLM), the design of distinct conversational personas, the process of generating conversations, the conversion of text to speech, and the concatenation of audio dialogues as displayed in Figure above. Each stage is carefully designed to ensure the creation of coherent, contextually relevant, and diverse audio conversations. By leveraging a combination of advanced models and fine-tuned techniques, we aim to produce high-quality synthetic dialogues that maintain consistency in character voices and offer a realistic conversational experience. The following sections detail the methodologies applied at each step, from LLM selection to audio post-processing, to achieve our desired outcomes.